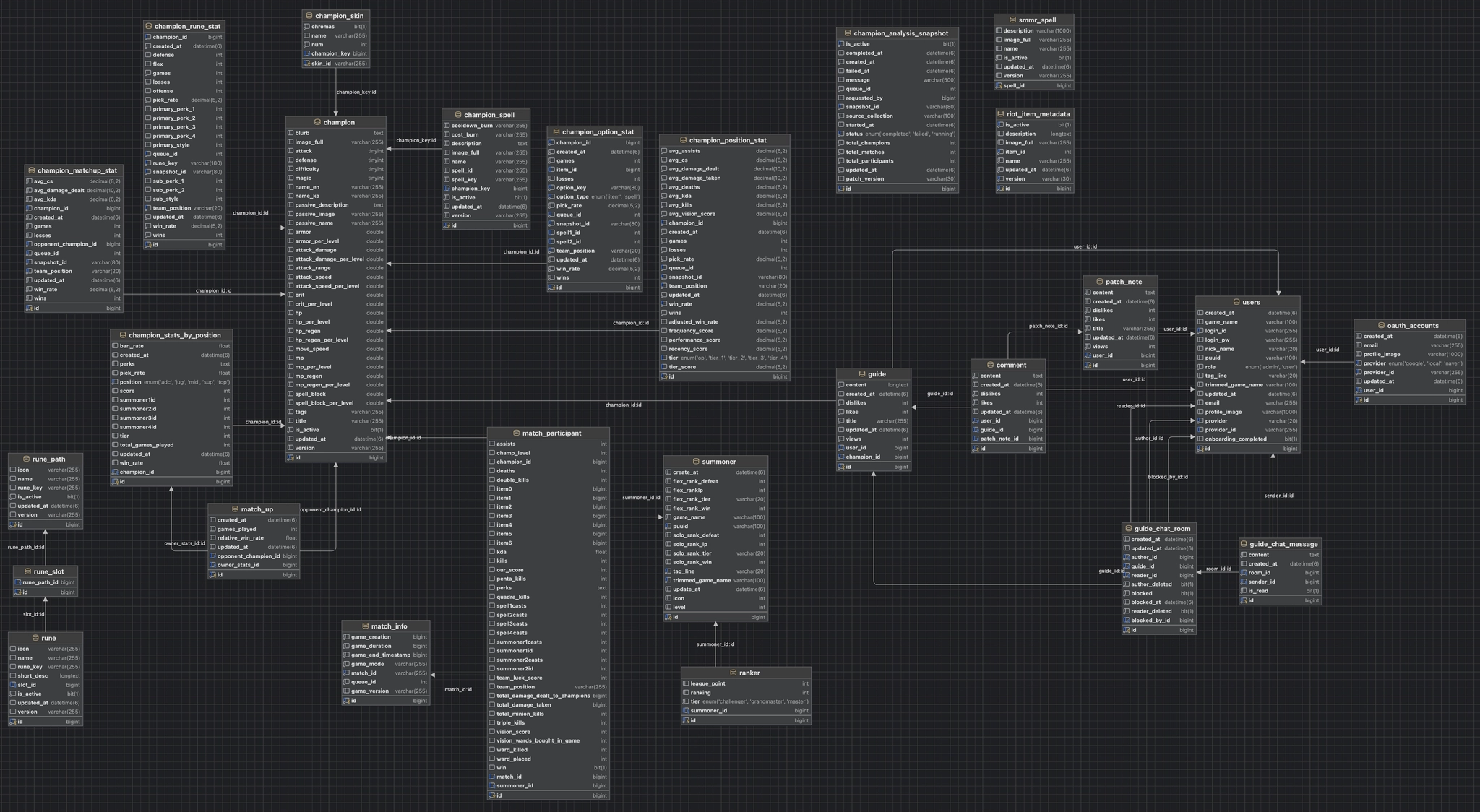
Overview
ARCANE은 Riot Games API를 기반으로 게임 데이터를 수집·분석하여 사용자에게 전적 검색과 다양한 게임 정보를 제공하는 플랫폼입니다.
단순한 전적 조회를 넘어 챔피언 분석, 패치노트, 랭킹, 공략 게시판, 실시간 채팅 등 다양한 기능을 하나의 서비스에서 제공하며, 사용자에게 보다 의미 있는 데이터를 전달하는 것을 목표로 개발했습니다.
Role
-
01
API / Worker / AI Server 3개 서버로 백엔드 구조 분리
-
02
Riot 배치 작업을 Kafka jobId 기반 비동기 처리로 전환
-
03
전적 검색 API 지연 원인 분석: 평균 13.6초 / p95 35.5초 기준 개선
-
04
챔피언 분석 API 응답을 5~9초 -> 0.6~0.8초 수준으로 단축
-
05
Elasticsearch 적용으로 검색 응답을 4.005ms -> 1.067ms로 개선
-
06
Redis Distributed Lock으로 동일 전적 검색 중복 Riot API 호출 제어
-
07
Challenger 300명 / Grandmaster 700명 랭킹 데이터 캐시 갱신 구조 구현
-
08
Prometheus/Grafana, ELK 기반 운영 지표와 로그 추적 환경 구성
Project Highlights
MSA
API / Worker / AI
Kafka
비동기 처리
Redis Lock
동시성 제어
AWS
EC2 / S3
Docker Compose
서비스 운영
GitHub Actions
CI/CD
Monitoring
Prometheus / Grafana / ELK
Champion API
93% 응답 개선
Elasticsearch
검색 성능 개선
Why MSA?
API Server
- 사용자 요청 처리
- 인증 및 API 응답
- 빠른 응답 유지
Worker Server
- Riot API 데이터 수집
- 장시간 배치 작업 처리
- Kafka Consumer 기반 작업 수행
AI Server
- AI 모델 추론
- 게임 분석 결과 생성
- 독립적인 AI 서비스 운영
사용자 요청과 장시간 작업을 분리하여 서비스 응답성을 유지하고, 각 서버가 독립적으로 확장 가능한 구조를 설계했습니다.
Features & Demo
소환사의 최근 20게임, 숙련도, 승률, 라인 통계를 보여주고 게임 지표 기반 AI 점수와 이벤트 흐름을 제공합니다.
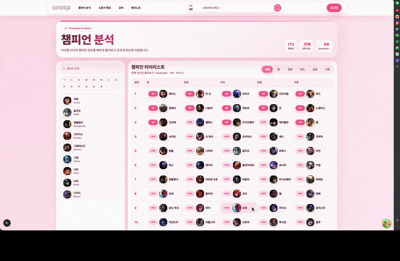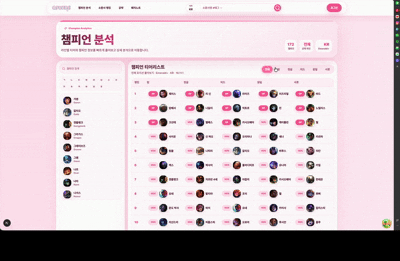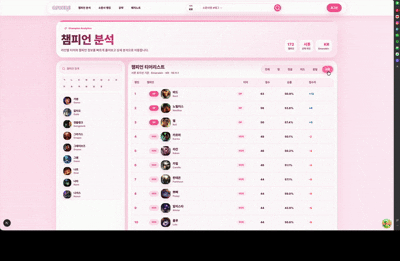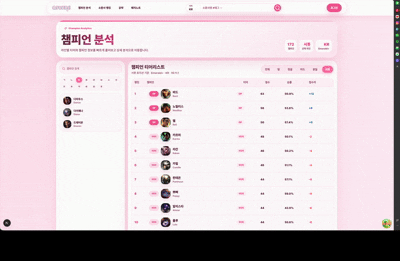
상위 티어 랭커 데이터를 기반으로 RFM 분석을 수행하고 라인별 OP, 1티어부터 5티어까지 구분해 제공합니다.
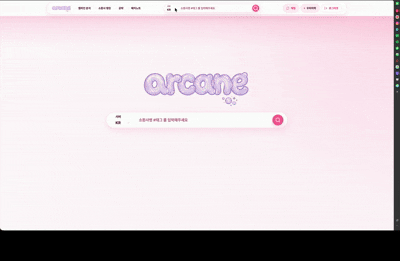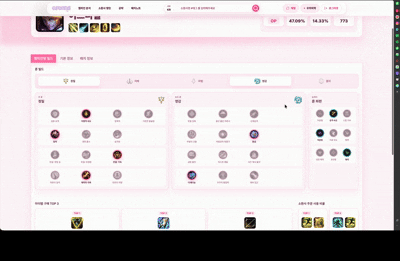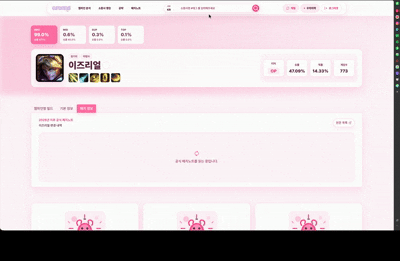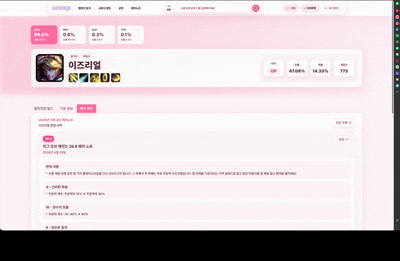
승률, 픽률, 아이템, 주문, 룬 통계와 패치 이력을 함께 제공하고 챔피언별 공략 게시판을 연결합니다.
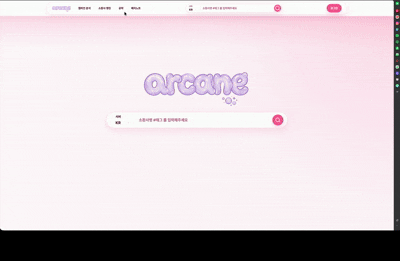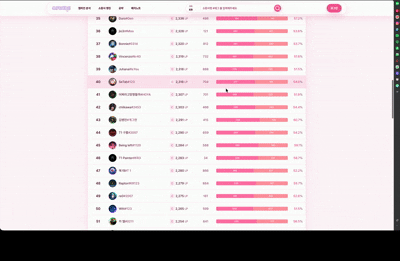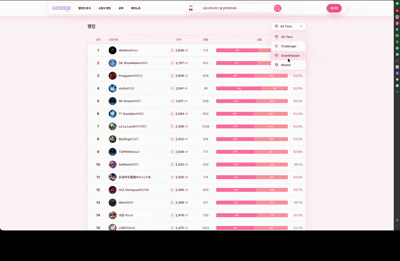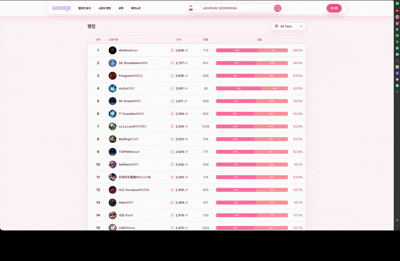
Challenger, GrandMaster, Master 티어 유저의 순위와 승률, 점수를 랭킹 순으로 제공하고 30분마다 자동 갱신합니다.

구글과 네이버 OAuth를 통해 가입할 수 있으며 닉네임 랜덤 제공 및 중복 체크 흐름을 구성했습니다.
Markdown Editor로 공략을 작성하고, 공략 작성자에게 실시간 채팅으로 추가 질문을 보낼 수 있습니다.
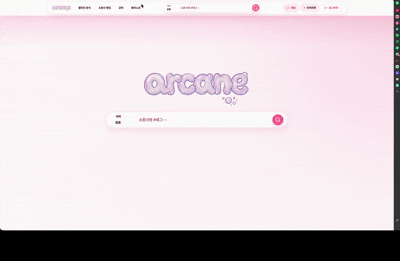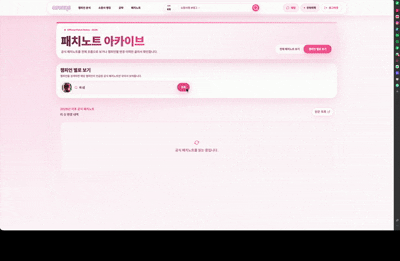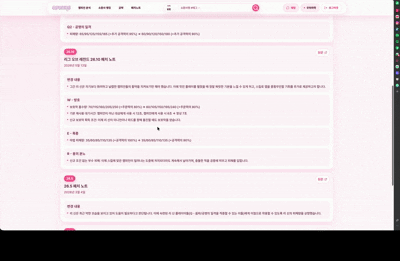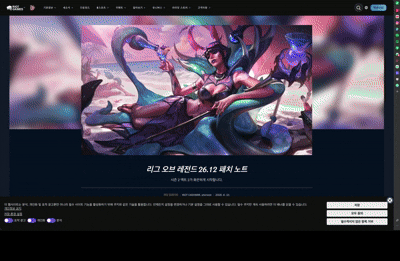
Riot 원본 패치노트를 인용해 정리하고 챔피언별로 적용된 패치 이력을 구분해 확인할 수 있게 했습니다.
서버 자원, 로그, 랭킹 갱신, 게임 데이터 수집 상태를 확인하고 오래 걸리는 작업의 진행 프로세스를 로그를 바탕으로 실시간 추적합니다.
System Architecture
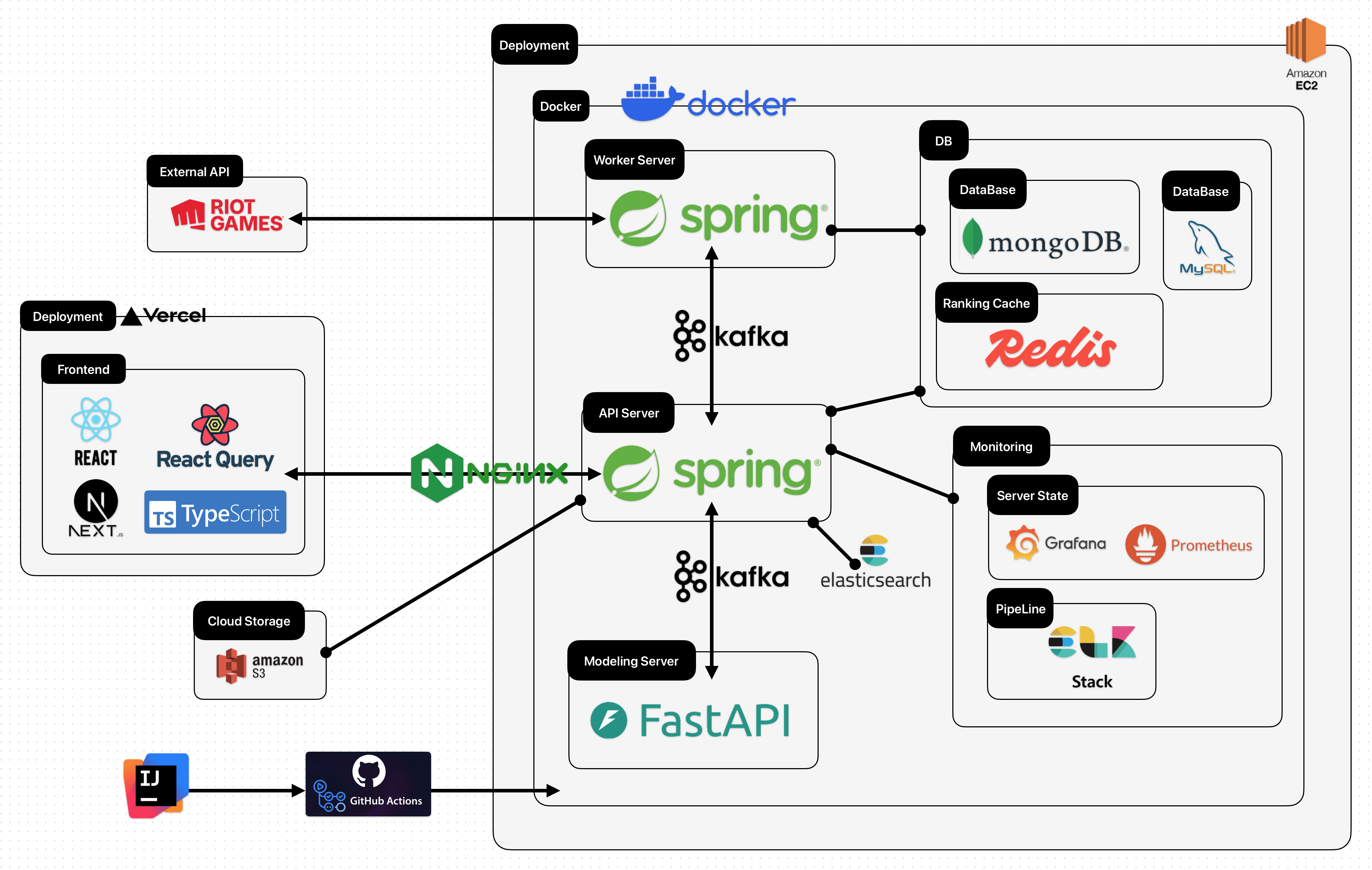
Operational Architecture
-
01
Client
서비스 요청 진입
-
02
Nginx
Reverse Proxy와 HTTPS 처리
-
03
API Server
인증, 응답, 이벤트 발행
-
04
Kafka
장시간 작업 메시지 큐잉
-
05
Worker Server
Riot 데이터 수집과 분석 처리
-
06
MongoDB
Match Raw Data 저장
-
07
MySQL
조회용 정형 데이터 저장
-
08
Redis
캐시와 Distributed Lock
-
09
Prometheus
메트릭 수집
-
10
Grafana
운영 지표 시각화
-
11
ELK
로그 검색과 장애 분석
-
12
Administrator
운영 상태 확인과 대응
Kafka Data Flow
사용자 요청은 API Server에서 짧게 수신하고, Riot 데이터 수집과 챔피언 분석처럼 오래 걸리는 작업은 Kafka 기반 비동기 흐름으로 분리했습니다.
-
01
Client
전적 검색과 분석 요청 발생
-
02
API Server
요청 검증 후 작업 이벤트 발행
-
03
Kafka Topic
jobId 기반 작업 메시지 큐잉
-
04
Worker Server
Consumer가 작업 메시지를 가져와 처리
-
05
MongoDB
Match Raw Data 저장
-
06
Champion Analysis
랭커 데이터 기반 통계 계산
-
07
MySQL
조회용 분석 결과 저장
-
08
Kafka Ack
Worker 처리 완료 후 작업 상태 전달
-
09
API Server
처리 상태와 저장 결과 확인
-
10
User Response
완료된 분석 결과를 조회 응답으로 제공
Deployment & Operations
기능 구현 이후에도 API Server, Worker Server, AI Server를 독립 컨테이너로 운영하고, 배포 자동화와 모니터링을 함께 구성해 서비스 상태를 지속적으로 확인할 수 있도록 설계했습니다.
CI/CD Pipeline
-
01
GitHub Push
main 브랜치 변경 사항을 기준으로 배포 workflow를 시작합니다.
-
02
GitHub Actions
API Server, Worker Server, AI Server 빌드 작업을 실행합니다.
-
03
Docker Image Build
서버별 실행 환경을 Docker 이미지로 패키징합니다.
-
04
GHCR Push
빌드된 이미지를 GitHub Container Registry에 업로드합니다.
-
05
EC2 Pull
AWS EC2에서 최신 컨테이너 이미지를 pull합니다.
-
06
Docker Compose
docker compose up -d로 서비스 컨테이너를 갱신합니다.
-
07
Deploy
Nginx와 HTTPS 환경에서 최신 서비스를 운영합니다.
Runtime Environment
AWS EC2
- API Server 운영
- Worker Server 운영
- AI Server 운영
Docker Compose
- API / Worker / AI Server, Kafka, Redis, MongoDB, MySQL을 하나의 compose 파일에서 관리
- 서비스 의존성 관리
- 운영 환경 일관성 유지
- 신규 배포 시 컨테이너 자동 교체
Nginx Reverse Proxy
- 외부 요청 진입점 구성
- API 요청 라우팅
- HTTPS 트래픽 처리
Certbot HTTPS
- SSL 인증서 발급
- HTTPS 적용
- 인증서 갱신 기반 마련
AWS S3
- 공략 게시판 이미지 저장
- 정적 파일 저장소 분리
- 애플리케이션 서버 부하 분산
Monitoring
Prometheus
Spring Actuator와 Micrometer 기반 메트릭 수집
- HTTP Request
- JVM Metric
- Server Resource
Grafana
운영 지표를 대시보드로 시각화
- JVM Heap
- CPU
- Memory
- HTTP Request Count
- HTTP Response Time
- Thread
ELK
Logstash, Elasticsearch, Kibana 기반 로그 추적
- API Log
- Worker Log
- Exception
- Job Tracking
- Trace 검색
Operational Features
Why Technology?
Kafka
- 비동기 처리
- 서버 간 결합도 감소
- 사용자 요청과 배치 작업 분리
Redis
- Cache
- Distributed Lock
- 외부 API 중복 호출 방지
MongoDB
- Match Raw Data 저장
- 유연한 스키마
- 분석 데이터 활용
Elasticsearch
- 자동완성
- 전문 검색
- LIKE 검색 개선
Prometheus / Grafana
- JVM Heap
- CPU / Memory
- HTTP Request Count / Response Time
- Thread 모니터링
ELK
- API Log / Worker Log
- Exception / Job Tracking
- Trace 검색과 장애 분석
Improvements
장시간 Riot 작업으로 인한 API 응답 지연과 서버 간 결합
상황 1- 일반 API 응답과 Riot API 기반 배치 작업을 단일 서버에서 함께 처리
- 서버를 나누더라도 HTTP 직접 호출 구조에서는 요청 서버가 장시간 작업 완료까지 대기
- 전적 검색 API 평균 약 13.6초, p95 약 35.5초까지 증가하고 timeout / 재시도 / 장애 전파 위험 발생
- API Server, Worker Server, AI Server 분리
- Kafka 기반 작업 요청 이벤트 발행으로 서버 간 결합 완화
- API Server는 사용자 요청과 이벤트 발행에 집중하고, Worker / AI Server가 데이터 수집과 모델 추론을 전담
이를 통해 사용자-facing API가 장시간 배치 작업을 직접 수행하지 않게 되었고, 랭킹 업데이트나 데이터 분석은 Kafka jobId 기반 비동기 작업으로 처리되도록 개선했습니다.
| count | 기존 HTTP 순차 | Kafka 배치 | 개선율 |
|---|---|---|---|
| 10 | 737ms | 92ms | 87.52% |
| 50 | 2,239ms | 83ms | 96.29% |
| 100 | 4,332ms | 88ms | 97.97% |
| 200 | 8,360ms | 116ms | 98.61% |
챔피언 통계 조회 시 반복 계산으로 인한 응답 지연
상황 2- 챔피언 티어 리스트와 상세 통계를 요청 시점마다 조회하고 계산
- 초 단위 실시간성이 낮은 데이터에도 반복 계산 비용 발생
- 기존 /statistics/* 계열 API에서 약 5초~9초 수준의 응답 지연
- Worker Server가 MongoDB의 Match Participant Raw Data를 사전 분석
- 승률, 픽률, 포지션별 통계, 아이템/스펠/룬 통계를 MySQL 분석 테이블에 저장
- 조회 시 계산 부담을 줄이고 분석 API 응답 시간 단축
프론트는 /analysis/* API를 통해 미리 계산된 결과만 조회하게 되었고, 챔피언 분석 API 응답은 약 93% 감소한 평균 약 0.6초~0.8초 수준으로 단축되었습니다.
LIKE 기반 검색의 한계와 Elasticsearch 개선
상황 3- 소환사 자동완성과 공략글 검색 모두 MySQL LIKE %keyword% 방식에 의존
- 검색창 입력처럼 반복 호출되는 기능에서 DB 부하 누적
- Markdown 기반 LONGTEXT 본문 검색은 데이터 증가에 따라 확장성 한계 발생
- gameName, tagLine, riotId를 Elasticsearch에 색인하고 n-gram 기반 자동완성 검색
- 공략글 title, content, championNameKo, championNameEn, authorName 색인
- 검색은 Elasticsearch, 정합성 조회는 MySQL로 역할 분리
검색은 Elasticsearch가 담당하고, 정합성이 필요한 상세 데이터 조회는 MySQL이 담당하는 구조로 분리했습니다.
| 검색어 | DB LIKE 평균 | Elasticsearch 평균 | 개선율 |
|---|---|---|---|
| hide on bush#kr | 27ms | 15ms | 44.44% |
| hide | 31ms | 10ms | 67.74% |
| a | 48ms | 9ms | 81.25% |
| 방식 | 평균 응답 시간 |
|---|---|
| MySQL LIKE 검색 | 4.005ms |
| Elasticsearch 검색 | 0.960ms |
| ES 결과 기반 MySQL 상세 조회 | 0.107ms |
| Elasticsearch 경로 합산 | 1.067ms |
운영 모니터링 도구 부재와 MSA 로그 추적 어려움
상황 4- API Server, Worker Server, Kafka, Redis, MongoDB, MySQL이 함께 동작
- 단순 콘솔 로그만으로 MSA 환경의 장애 원인 추적이 어려운 상태
- Riot API 401/504, Kafka 연결 실패, MongoDB codec 오류 등 장애 유형 다양
- API Server와 Worker Server의 로그 형식 통일
- serverType, task, method, status, traceId, jobId를 로그에 포함
- 시간 단위 로그 파일 저장과 관리자 페이지 기반 API/Worker 로그 조회 구성
Prometheus/Grafana로 JVM heap, CPU, HTTP 요청 수, 최대 응답 시간, thread 수를 확인할 수 있게 했고, ELK 스택을 통해 로그를 구조화하여 검색할 수 있는 운영 기반을 마련했습니다.
랭킹 업데이트의 API 요청 문제 및 안정성 부족
상황 5- 랭킹 데이터는 Riot API 호출량이 많고 업데이트 시간이 긴 데이터
- 랭킹 페이지 접근마다 Riot API나 DB를 직접 조회하면 응답 지연과 Rate Limit 위험 증가
- 업데이트 중 기존 캐시를 덮어쓸 경우 불완전한 데이터 노출 가능성
- Worker Server가 Riot API로 Challenger 300명, Grandmaster 700명 등 랭킹 데이터 수집
- 수집된 랭킹 데이터를 Redis에 저장해 조회 API 응답 속도 개선
- 임시 키 구성 후 실제 키로 교체하는 Atomic Swap 방식 적용
랭킹 조회 API는 Redis 캐시를 기준으로 빠르게 응답하고, 업데이트 중에도 기존 랭킹 데이터를 안정적으로 제공할 수 있도록 개선했습니다.
캐시 미스 상황에서 중복 외부 API 호출 발생
상황 6- 동일 소환사 전적을 여러 사용자가 동시에 검색하는 상황 발생
- DB나 캐시에 데이터가 없을 때 여러 요청이 Riot API를 중복 호출
- 중복 요청 누적으로 Rate Limit, 전적 조회 지연, 조회 실패 가능성 증가
- 소환사 PUUID 또는 Riot ID 기준 Redis Distributed Lock 적용
- 첫 요청만 Riot API를 호출하고 나머지 요청은 Lock 해제 대기
- Lock 해제 후 DB 또는 캐시에 저장된 결과를 재사용하는 조회 흐름 구성
이를 통해 동시성 제어, 외부 API Rate Limit 대응, Redis 기반 서비스 안정성 확보를 함께 고려했습니다.
Redis Distributed Lock Flow
-
01
User A
동일 소환사 최초 검색 요청
-
02
Redis Lock
PUUID 또는 Riot ID 기준 Lock 획득
-
03
Riot API
최초 요청만 외부 API 호출
-
04
MongoDB
Match Raw Data 저장
-
05
MySQL
조회용 전적 결과 저장
-
06
Unlock
저장 완료 후 Lock 해제
-
07
Users B, C, D
동시 검색 요청은 대기 후 재조회
-
08
DB Read
저장된 데이터를 재사용해 응답
동시에 여러 사용자가 같은 소환사를 검색해도 최초 요청만 Riot API를 호출하고, 이후 요청은 저장된 데이터를 재사용하는 구조입니다.
공략 이미지 파일 저장 위치와 배포 환경 분리 문제
상황 7- 공략글 이미지를 서버 로컬에 저장할 경우 배포 환경에 종속
- EC2 재배포, 컨테이너 교체, 서버 확장 시 파일 유실 위험
- 애플리케이션 서버와 정적 파일 저장소가 분리되지 않아 접근 경로 불일치 가능
- 이미지 업로드 API를 AWS S3 기반으로 구성
- 프론트 공략 작성 로직에서 업로드 후 반환된 URL을 Markdown 본문에 삽입
- 애플리케이션 서버와 정적 파일 저장소를 분리해 배포 안정성 확보
파일 업로드 API, 클라우드 스토리지, 배포 환경, 프론트-백엔드 연동을 함께 고려한 실서비스형 저장 구조로 정리했습니다.
Insights
System Structure
서비스의 성능은 기능보다 시스템 구조에 더 큰 영향을 받는다는 점을 경험했습니다.
Role Separation
장시간 작업과 사용자 요청을 분리하고, 시스템의 역할을 명확히 나누는 설계의 중요성을 배웠습니다.
Operation First
서비스는 개발보다 운영이 더 중요하며, 모니터링과 로그를 통한 지속적인 개선이 필수적이라는 점을 경험했습니다.