Overview
공장 내 작업자와 지게차가 서로 직접 보이지 않는 사각지대 충돌 위험이 존재하며, 단일 카메라나 단순 객체 검출만으로는 현장의 위치 관계와 미래 이동 패턴을 안정적으로 판단하기 어렵습니다.
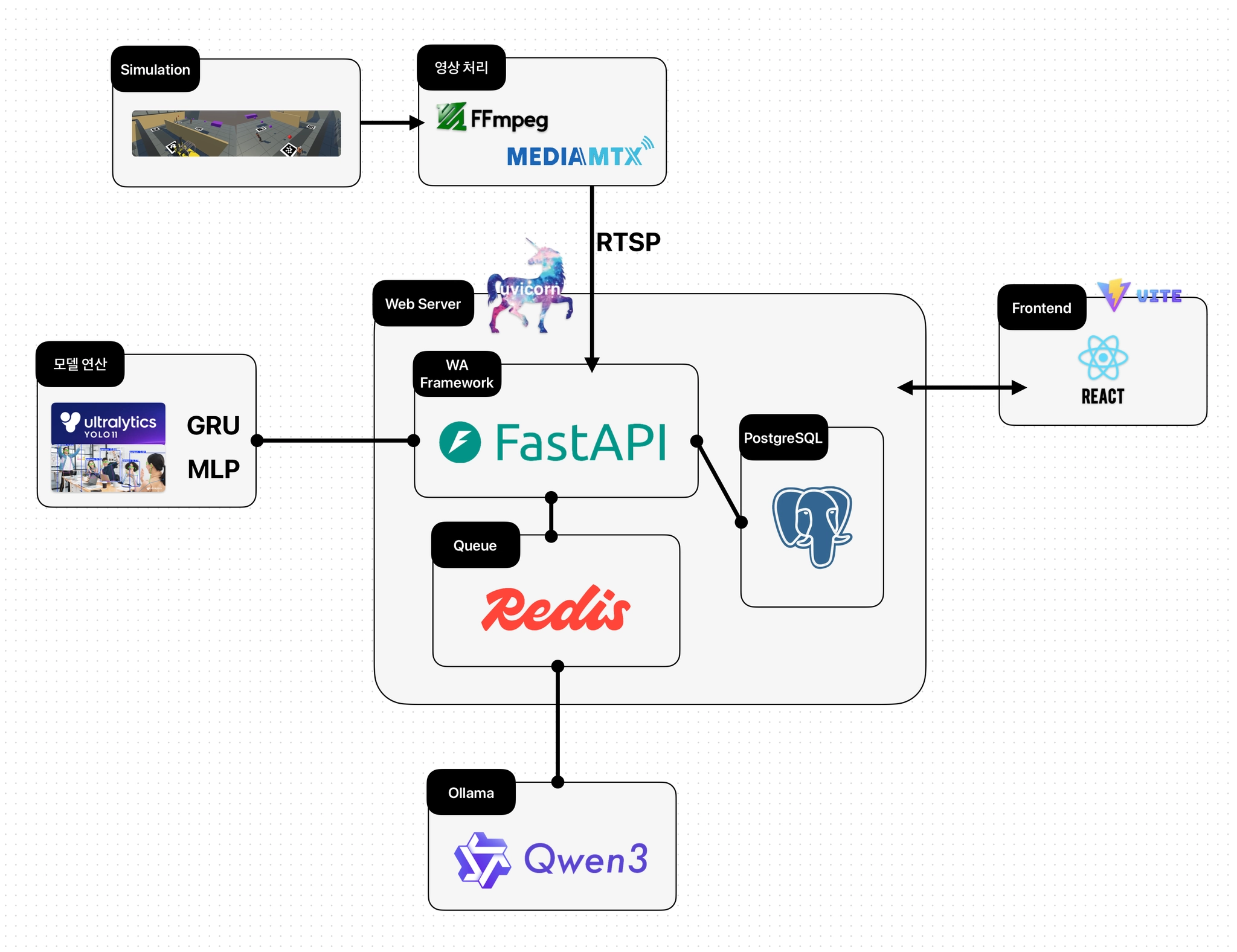
두 대의 RTSP 카메라 영상을 멀티뷰로 입력하고, 검출된 객체 위치를 ArUco Homography 기반 BEV 절대좌표계로 통합했습니다.
좌표 시퀀스를 GRU 기반 Fusion Model에 입력해 실시간 충돌 위험을 Warning / Danger 단계로 예측하고, Spring Backend를 통해 MQTT 알림, PostgreSQL 저장, LLM 사고 리포트 생성 흐름으로 통합했습니다.
Role
-
Vision Pipeline Engineering
Unity 제조 시나리오 구성, FFmpeg + MediaMTX 기반 RTSP 영상 스트리밍 파이프라인 구축
-
Multi View Coordinate System
YOLO 객체 검출 결과의 ArUco Homography 기반 BEV 절대좌표 변환, 동일 좌표계 위험 판단 구조 구현
-
AI Risk Prediction
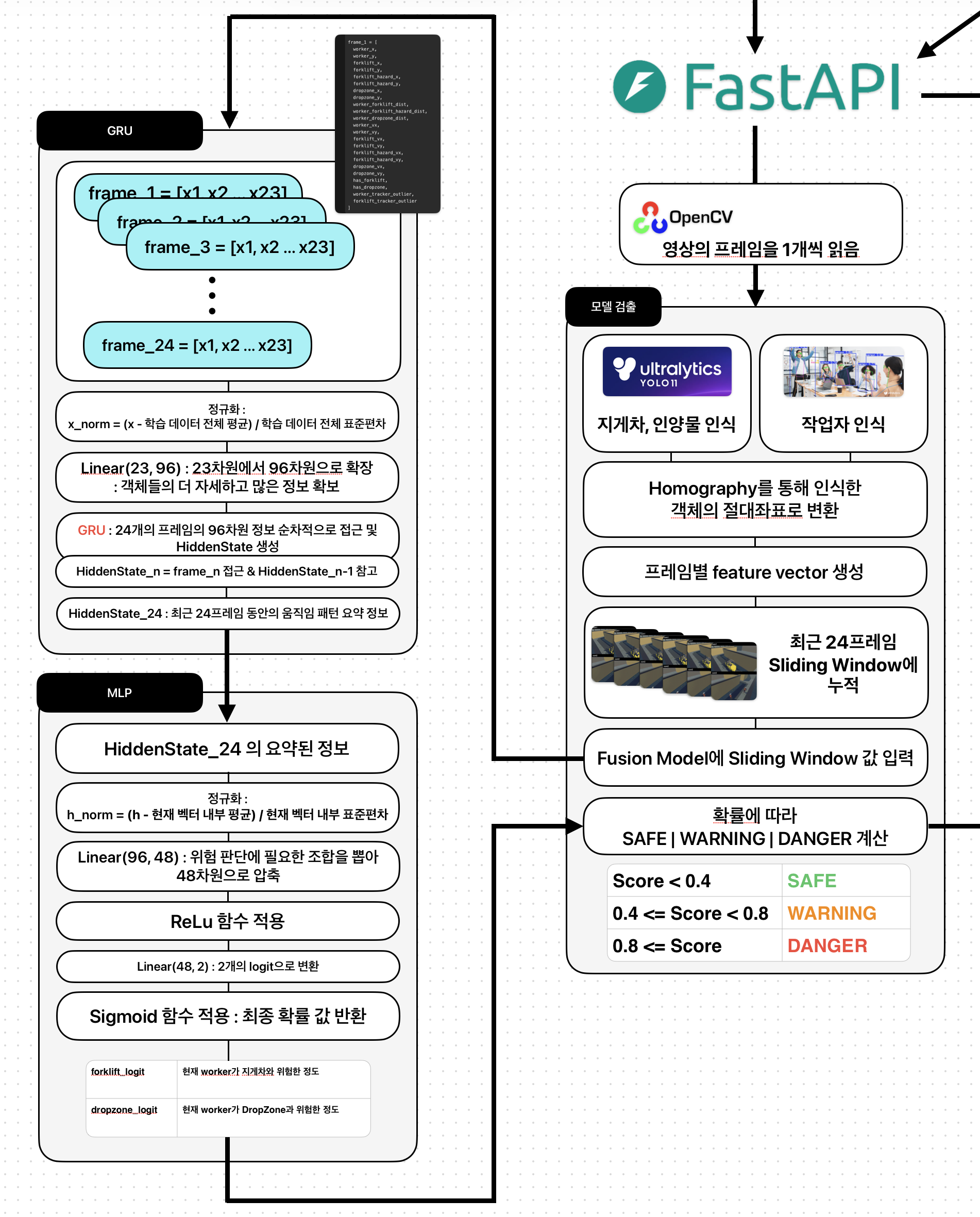
YOLO-Pose / Custom YOLO 검출 결과 Feature 변환, 24 Frame 시계열 기반 GRU Fusion Model 적용
-
Real-Time Optimization
카메라/모델 병렬 처리, pose cache 적용, 3.145 FPS -> 10.148 FPS 실시간 처리 성능 개선
-
Backend Integration
PostgreSQL 사고 로그 저장, MQTT 위험 알림 연동, Qwen 기반 LLM 사고 리포트 생성 서비스 흐름 통합
Project Highlights
RTSP Multi View
멀티 카메라 영상 입력
BEV Coordinate System
ArUco Homography 기반 절대좌표 변환
YOLO Detection
작업자 / 지게차 / 인양물 객체 검출
GRU Fusion Model
24 Frame 시계열 기반 위험 예측
MQTT Alert
실시간 위험 알림
LLM Report Generation
Qwen 기반 사고 리포트 자동 생성
10.148 FPS
실시간 처리 성능 개선
프로젝트 시연
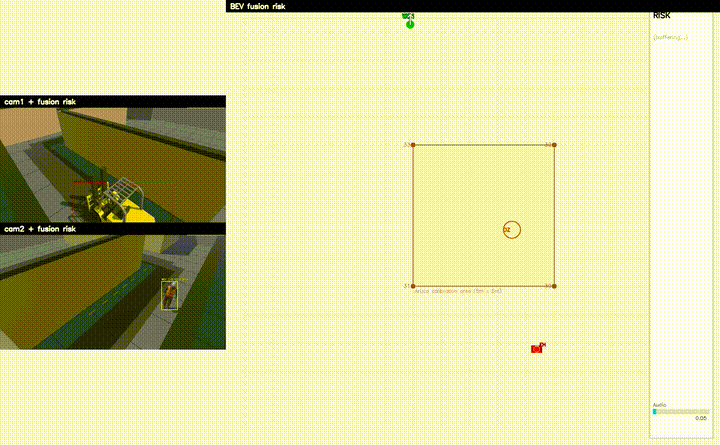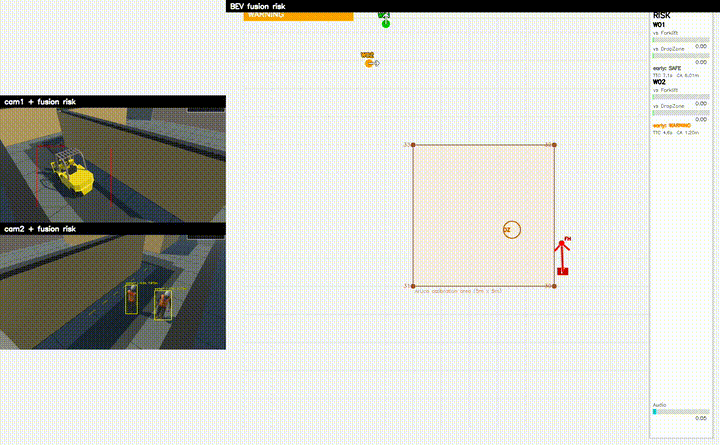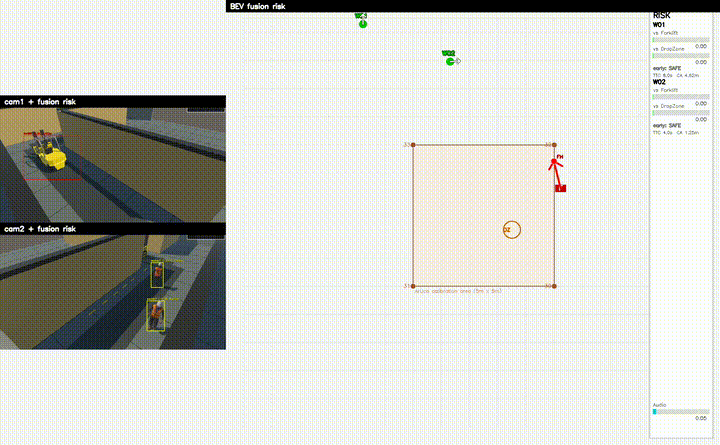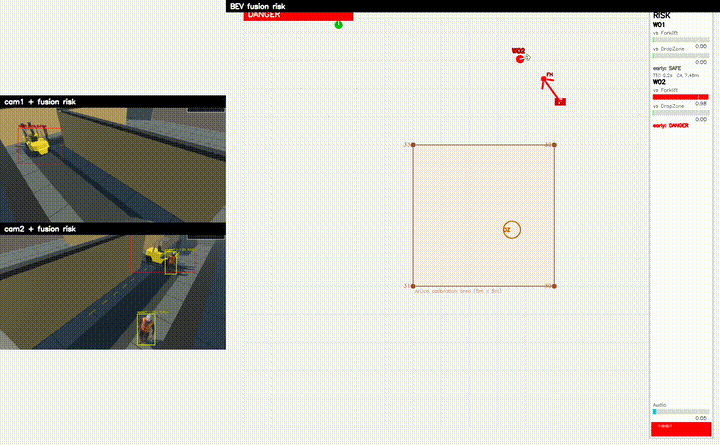

시스템 아키텍처
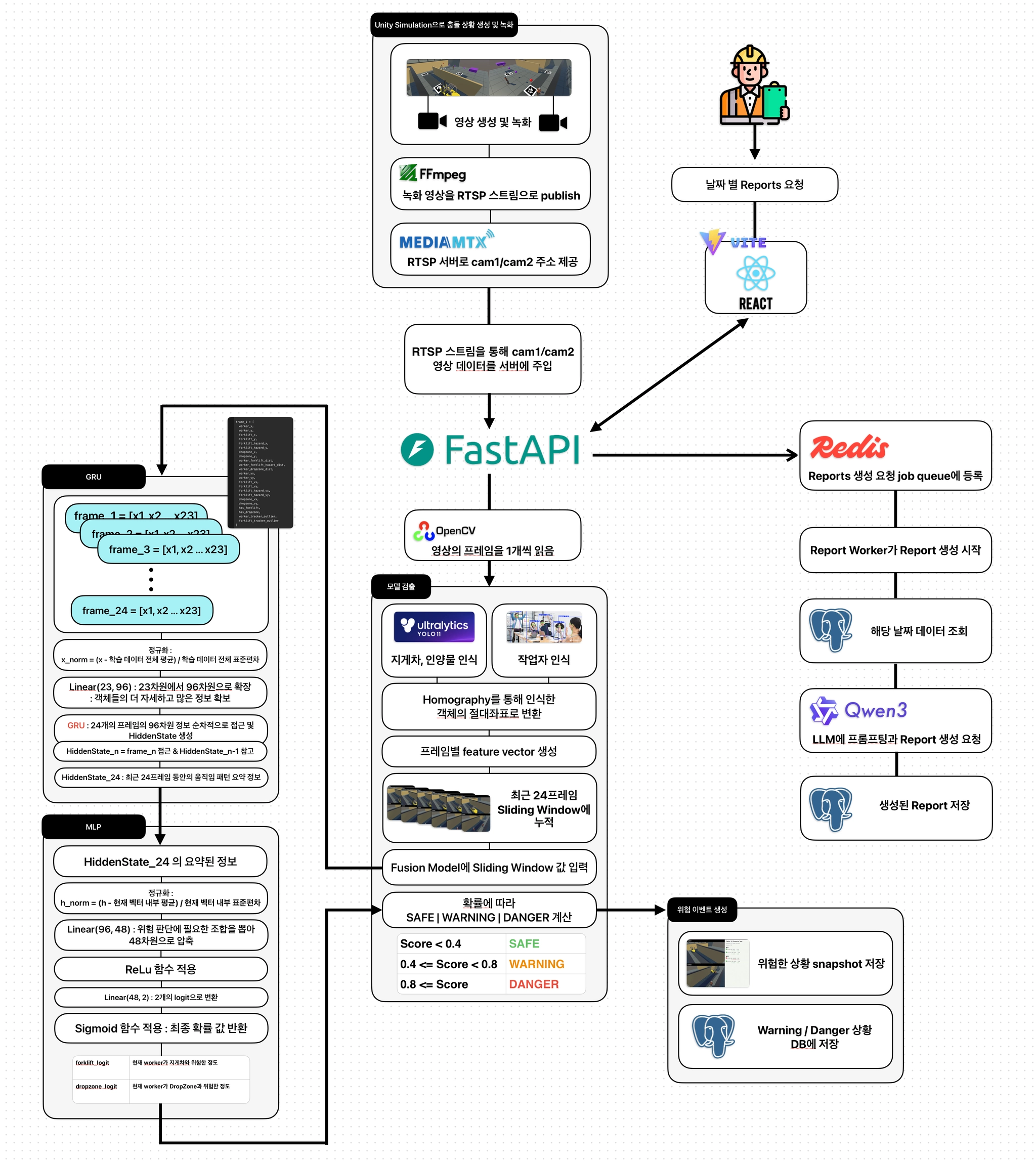
Backend Flow
AI 추론 결과를 단순 출력하는 것이 아니라, 위험 감지부터 저장, 알림, 사고 리포트 생성까지 하나의 서비스 흐름으로 구성했습니다.
-
01
RTSP Camera
공장 사각지대 멀티뷰 영상 입력
-
02
AI Detection Pipeline
작업자, 지게차, 인양물 객체 검출
-
03
Fusion Risk Prediction
BEV 좌표 시계열 기반 위험 예측
-
04
Spring Backend
추론 결과를 서비스 이벤트로 통합
-
05
MQTT Alert
현장 위험 알림 전송
-
06
PostgreSQL Accident Log
사고 로그와 스냅샷 메타데이터 저장
-
07
LLM Report Generation
Qwen 기반 사고 리포트 생성
Model Responsibility
Custom YOLO

- 지게차와 인양물을 탐지하고 BEV 좌표 변환을 위한 위치 정보를 제공합니다.
- forklift / box 검출 결과를 위험 판단 Feature로 변환
- Fusion Model 입력을 위한 객체 기준점 생성
YOLO-Pose
- 작업자의 keypoint를 추출하고 위험 판단 Feature 생성에 활용합니다.
- 작업자 위치를 BEV 절대좌표로 변환
- pose cache와 함께 실시간 추론 성능 개선에 활용
Fusion Model
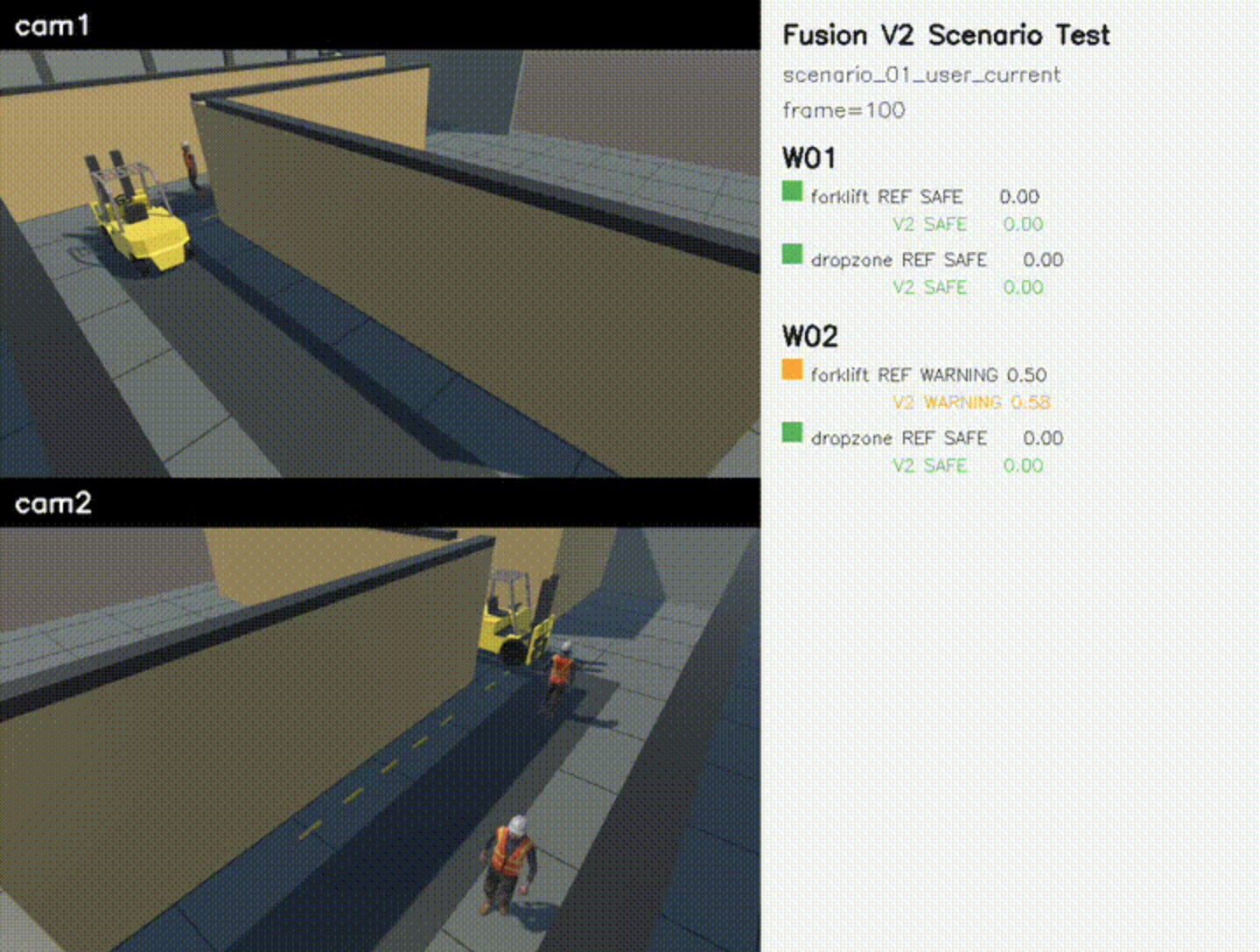
- 최근 24프레임 BEV 좌표 시계열 데이터를 입력받아 미래 충돌 위험을 예측합니다.
- 작업자, 지게차, FH 기준점, DropZone Feature를 통합
- Warning / Danger 단계의 위험 판단 결과 생성
- Fusion V2는 절대좌표 기반 geometry_future 라벨로 구성한 별도 평가셋에서 측정한 확장 모델입니다.
개선 사항
단일 카메라만으로 사각지대 충돌 위험 판단의 어려움
상황 1- Cam1 또는 Cam2 단일 영상 기준 위치 관계 판단 한계
- 사각지대 내 지게차-작업자 충돌 위험 산정 불안정
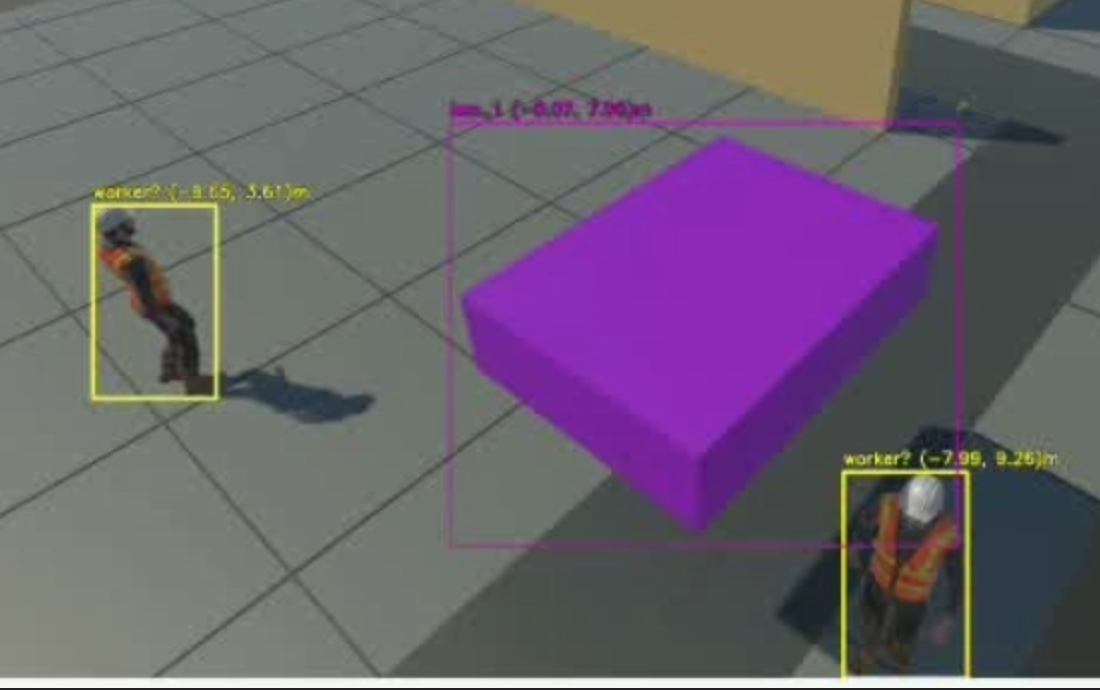
- 두 카메라 검출 결과의 ArUco Homography 기반 BEV 절대 좌표 변환
- 하나의 BEV 평면 기준 충돌 위험 계산 구조
멀티뷰 BEV 통합으로 단일 카메라 사각지대 판단 한계 를 보완하고, 동일 좌표계 기반 충돌 위험 산정 구조를 확보했습니다.
카메라 별 좌표 오차
상황 2- Cam1 / Cam2 간 동일 객체 절대좌표 불일치
- BEV 상 객체 위치 신뢰도 저하
- 카메라별 4개 ArUco Marker 기준 Homography 재생성
- cv2.findHomography 기반 픽셀 좌표의 BEV 절대좌표 변환
- 최종 캘리브레이션 기준 평균 재투영 오차 2.72e-7m ~ 4.58e-7m
카메라별 좌표 보정으로 BEV 위치 신뢰도를 높이고, 평균 재투영 오차 2.72e-7m ~ 4.58e-7m 수준의 좌표 정합성을 확보했습니다.
작업자 인식 불안정
상황 3- 일부 시나리오의 작업자 bbox / pose 검출 불안정
- Fusion 모델 작업자 입력 누락에 따른 위험 예측 실패
- YOLO11s-pose 적용 및 pose 입력 크기 640 유지
- 카메라 위치와 FOV 조정을 통한 작업자 프레임 점유율 확보
- 충돌 시나리오 3개, 총 45회 벤치마크 기준 작업자 detection 확률 1.00
작업자 검출 안정화로 Fusion 입력 누락을 줄이고, 45회 벤치마크 기준 작업자 detection 확률 1.00 을 확보했습니다.
위험 알림 지연
상황 4- 지게차 bbox 중심점 기준 위험도 계산
- 실제 충돌 가능성이 높은 전방부 기준점 부재
- Warning / Danger 판단 시점 지연
- 이전/현재 프레임 좌표 기반 진행 방향 벡터 추정
- 진행 방향 앞쪽 FH(Front Hazard) 기준점 추가
- FH offset 1.0m 적용 후 Danger 시점 최대 0.7s, 최소 0.15s 단축
FH 기준점 도입으로 실제 충돌 가능성이 높은 전방부를 기준으로 위험을 판단하고, Danger 판단 시점 최대 0.7s 단축 을 달성했습니다.
실시간 처리 성능 부족
상황 5- cam1 pose, cam2 pose, custom YOLO, fusion 순차 처리
- 단일 루프 중심 추론 구조로 인한 실시간성 부족
- 초기 성능 평균 3.145 FPS, frame당 0.320s
- 카메라 단위 병렬 처리와 모델 단위 병렬 처리 적용
- custom YOLO 입력 크기 640 -> 512 조정
- pose 2프레임 1회 추론 및 cache 재사용
- 45회 벤치마크 기준 평균 10.148 FPS, frame당 98.966ms
병렬 처리와 캐시 재사용으로 실시간 처리 성능을 3.145 FPS -> 10.148 FPS 로 개선하고, frame time을 0.320s에서 98.966ms 수준으로 줄였습니다.
| 단계 | 내용 | FPS | 직전 대비 FPS 향상 | 1 frame 처리시간 | 직전 대비 처리시간 감소 |
|---|---|---|---|---|---|
| 0 | 초기 serial 처리 | 3.145 FPS | - | 0.320s | - |
| 1 | 카메라별 병렬 처리 | 5.488 FPS | +74.5% | 0.183s | 43.0% 감소 |
| 2 | 모델별 병렬 처리 | 6.335 FPS | +15.4% | 0.158s | 13.5% 감소 |
| 3 | custom YOLO 이미지 크기 조정 | 7.364 FPS | +16.2% | 0.136s | 14.2% 감소 |
| 4 | pose 2프레임에 1번 추론 | 10.148 FPS | +37.8% | 0.099s | 27.0% 감소 |
* FPS 향상률 = ((신규 FPS - 직전 FPS) / 직전 FPS) ×
100
* Frame time 감소율 = ((직전 처리시간 - 신규 처리시간) /
직전 처리시간) × 100
장기 작업으로 인한 API 응답 지연
상황 6- Ollama 리포트 생성 완료까지 API 응답 대기
- 날짜 기반 리포트 생성 요청 약 71초 소요
- 목록 조회 API의 전체 HTML contents 반환으로 응답 크기 증가
- 리포트 생성 작업의 Redis 기반 Background Job 분리
- 작업 등록 후 job_id 즉시 반환 및 상태 조회 흐름 구성
- 목록 화면 전용 경량 조회 API 추가
Background Job 분리로 장시간 리포트 생성 작업이 사용자-facing API를 막지 않도록 개선했습니다. 또한 목록 화면에서는 전체 HTML contents를 반환하지 않고 필요한 메타데이터만 조회하도록 분리하여, 리포트 목록 응답 크기를 97,761 bytes에서 729 bytes로 줄이고 약 99.25% 감소를 확인했습니다.
사고 로그 검색 성능 개선
상황 7- 총 300,391건 사고 로그와 1000일 분산 조건 테스트
- Elasticsearch 도입 대비 낮은 날짜 조건 검색 효율
- 날짜 필터 중심 조회 패턴과 검색 엔진 선택의 불일치
- 날짜 정보 별도 컬럼 분리
- 조회 패턴 기반 PostgreSQL 복합 인덱스 적용
- 날짜 조건 검색 p50 0.097ms, Elasticsearch 대비 약 46배 개선
조회 패턴 기반 인덱싱으로 날짜 검색 p50 0.097ms를 달성하고, Elasticsearch 대비 약 46배 빠른 응답을 확인했습니다.
| 실험 항목 | 방식 | 평균 | p50 | p95 | 결과 |
|---|---|---|---|---|---|
| 날짜 컬럼 검색 | PostgreSQL Index | 0.480ms | 0.097ms | 0.660ms | 가장 빠름 |
| 날짜 컬럼 검색 | Elasticsearch Filter | 5.376ms | 4.528ms | 7.960ms | 상대적으로 높은 지연 |
공중 인양물의 DropZone 좌표 오차 및 위험 반응 손실
상황 8- 공중 인양물의 bbox 기준 절대좌표 변환 불안정
- 바닥 평면 기준 Homography 적용 한계
- DropZone 프레임 누락과 위험 상황 감지 손실
- 카메라 위치 조정과 bbox 중심 픽셀 기반 camera ray 계산
- 인양물 높이 교차점 기준 절대좌표 산출
- 반경 2.0m DropZone 적용 후 누락 프레임 0 / 120
DropZone 좌표 안정화로 raw/tracker 누락 프레임을 0 / 120까지 줄이고, 공중 인양물 위험 판단 누락을 감소시켰습니다.
| 항목 | 개선 전 | 개선 후 | 비고 |
|---|---|---|---|
| raw DropZone 누락 프레임 | 64 / 120 | 0 / 120 | 누락 프레임 없음 |
| tracker 후 DropZone 누락 프레임 | 48 / 120 | 0 / 120 | 누락 프레임 없음 |
| Danger frame | 0 | 20 | 위험 판단 누락 감소 |
| first_danger_frame | 없음 | 45 | 위험 판단 누락 감소 |
| W01 DropZone 최소 거리 | 1.433m | Danger 발생 | 1.4m 거리에서도 위험 알림 |
| W02 DropZone 최소 거리 | 1.801m | Danger 발생 | 1.8m 거리에서도 위험 알림 |
규칙 기반 Fusion 모델의 위험 판단 한계
상황 9- BEV 절대좌표, 거리, TTC, FH 기준점 기반 규칙 모델
- 복잡한 시나리오 증가에 따른 임계값과 예외 조건 증가
- 동적 이동 패턴 반영 한계
- 최근 24프레임 BEV 절대좌표 시계열 입력 구조
- 작업자, 지게차, FH 기준점, DropZone feature 구성
- GRU 기반 Fusion V2 위험 예측 모델
Fusion V2 학습 데이터는 실제 Unity 녹화 시나리오 7개와, SAFE / WARNING / DANGER 상황이 균형 있게 포함되도록 절대좌표 기반으로 절차적 생성한 synthetic 시나리오 450개를 결합해 구축했습니다. 그 결과 기존 Fusion V1 대비 F1-score는 84.9%에서 99.2%로 14.3%p 개선되었고, Accuracy는 92.2%에서 99.7%로 7.5%p 개선되었습니다.
| 항목 | 값 |
|---|---|
| 입력 | 24프레임 BEV 절대좌표 시계열 |
| Feature 수 | 23개 |
| 실제 녹화 시나리오 | 7개 |
| Synthetic 시나리오 | 450개 |
| 전체 window | 89,176개 |
| 학습 window | 67,096개 |
| 검증 window | 11,040개 |
| 모델 | 2-layer GRU |
인사이트
Data Representation & Real-Time AI
입력 데이터의 표현 방식과 형태가 모델의 예측 속도와 정확성을 결정한다는 점을 경험했습니다. 단순 bbox 좌표가 아니라 BEV 절대좌표, FH 기준점, DropZone, 최근 24프레임 시계열로 데이터를 재구성하면서 실시간 위험 예측의 품질을 높일 수 있었습니다.
AI Integration
산업 현장형 AI는 단순 모델 구현뿐 아니라 데이터 수집, 전처리, 추론 서비스, API, 저장소, 알림까지 하나의 시스템으로 통합될 때 실제 서비스 가치가 생긴다는 점을 느꼈습니다. RTSP 입력부터 객체 검출, 좌표 변환, 위험 판단, DB 저장, 리포트 생성까지 연결하며 백엔드 중심 AI 시스템의 병목을 직접 개선했습니다.